We were down. Here is what we’re doing better
Down
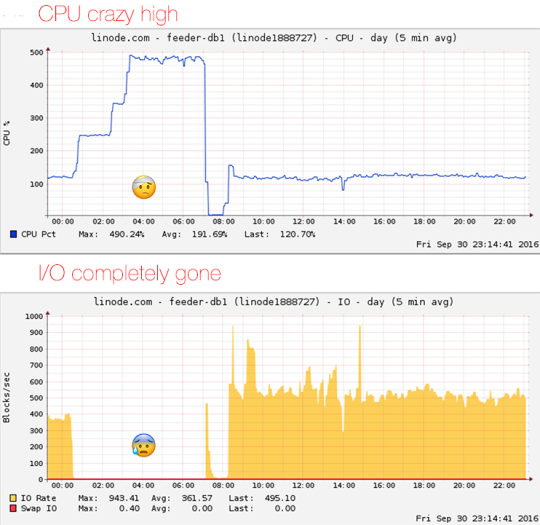
At 2016-09-30 00:30 GMT the feeder service went unresponsive. Our database server went into a perpetual spin cycle. It went completely unavailable to the outside world. Even using the equivalent of hooking in a screen to the physical server, Linode’s Lish, did not help. There was no terminal prompt and lots of kernel errors flashed across the screen.
The only thing to do at that point was a hard reboot. After that, things went back to normal. We’re implementing some measures for faster response times during incidents. We have also started setting up better channels for information for you when it happens.
Up
The server came up fine, and MySQL started an InnoDB repare due to the improper shutdown. After about 5 minutes, MySQL was running, app servers were responding and all feed crawler microservices were connected. At 2016-09-30 07:12 GMT, feeder was back.
Next steps
We realize that this downtime was a huge inconvenience. Our goal is to provide a stable, reliable service that our users can count on. We’re learning from the many things that went wrong. Here is what we are going to do better:
First thing: Complete lack of information. There were no updates on Facebook, Twitter, or our blog. As a user, you want to be able see why you’re not getting your feeds. We’re going to be setting up a statepage.io on status.feeder.co, that will act as the hub of information when incidents happen. Statuspage is a fantastic service that has become the norm for SaaS applications.
Second thing: Slow response time. Our on-call person was in bed sleeping at the time of the incident. In a moment of sleep deprived lapse of judgement, silent mode had been enabled. This means server alarm messages were not coming through. To solve this we are setting up a service that will trigger a call/text from a specific number, and make sure this number always triggers an auditory alert.
Third thing: Cryptic error messages. Our database server went unresponsive, but it was still running. Connections were active but no queries were being fulfilled. This caused our frontend app servers to wait for responses from the databases indefinitely and Passenger’s request queue became full. This triggered a standard 503 “Not enough resources available” error message. As a user, this was most likely extremely confusing and unhelpful. Our designer is on the task of creating a better, more helpful error page. Hopefully you’ll never have see it…
In closing
As started earlier, we’re really sorry for the incident and going to work hard to improve the experience. Mistakes happens, planets mis-align, and servers go down. It is an inevitable fact of life. What we can do is be a little better when it does. Stay tuned and we’ll keep you updated.