Removing duplicate posts
Yesterday I wrote about an issue we had causing many duplicate posts for our users.
I also wrote that it would be difficult to remove those duplicate posts because of the sheer size of our post database. (500 GB+). After thinking about it for a while I realised that there is a fairly easy way to at least clear away a large subset of these posts.
Key Value Store
As described in the previous blog post, our post database is structured as a massive key value store. I’ve looked into using MongoDB or some similar hot name in that area to do it this way. One huge benefit with MongoDB is that it comes with pretty nice automatic sharding of collections, which means that you can have multiple database servers with a sub-collection of the data. When you add new database servers, MongoDB will automatically figure out how to optimally arrange this data.
With MySQL it’s not as easy, and has to be a lot more manual. There you have to handle multiple servers in code and make sure to keep track of which servers contain which subset of data. If you add another server you also have to in some way automatically shift all the data.
Since it’s so easy to upgrade servers on Linode it’s never really become an issue. Whenever the database server gets full I just shut it down for an hour and upgrade to the next level, and dream of the day I can spend some time to actually shard the data or set up a good compression of old posts (Amazon Glacier comes to mind).
The database
The current setup with the feeder pro database is actually just one huge MySQL server, and one InnoDB database for most data, and another InnoDB database for the post database. This has come up recently because of a configuration setting that is off by default in MySQL, to store all the data in one single file on disk. With InnoDB, MySQL allocates a single massive file on disk that it can do whatever it wants with. To begin with it’s fairly small, but as your data grows so does this file.
It does not shrink this file ever. If you remove a lot of data MySQL won’t shrink the file. If you once had 700 GB of data in your InnoDB file and the server disk space runs out, you simply cannot go crazy with “DELETE * FROM *” because that won’t help you at all. After you removed half of the data in the database your InnoDB file will still be 700 GB. And as far as I know the only way to shrink it is to export your entire database and import it again into another database.
This seems very weird and has caused a lot of headaches and money spent on panicky server upgrades. A couple of months ago I found the configuration setting: “innodb_file_per_table=1″ which will fix this problem, for any new tables. One sunday morning I decided to take the bull by the horns and move all post data into a separate MySQL database and be done with it. While doing the migration I was also able to delete a lot of data, saving a lot of space on the server.
The Key Value Store
When a database get’s to a certain size it’s impossible to query it without using indexes. If you don’t hit a good index your database will have to read all of the data on disk, which is extremely slow. However another problem is that when your index gets to a certain size it can’t be held in RAM either, which means that it also has to be read from disk.
To fix this problem feeder pro has conceptually created a basic key value store for all posts, where the MySQL post id is the key. Doing queries on IDs is guaranteed to be extremely fast, and because of that it’s was not necessary to move to MongoDB.
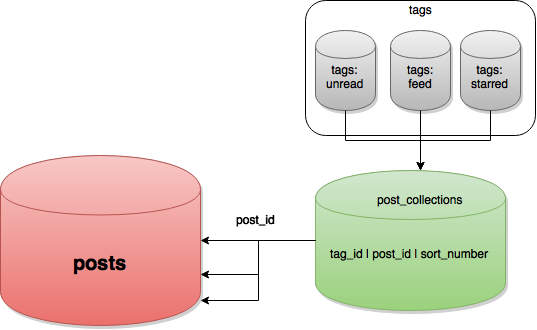
With feeds and posts and unreads and stars order is very important, and keeping track of those requires something. To solve that problem we store all feed<->post relations in a list with just the post id and a “tag id” and a sort number. The “tag id” is a unique tag that can be either a “feed”, an “unread list” or a “starred posts list”.
When a post is marked as starred for example, the user’s starred post tag is looked up, and the post id is added to that “post collection”. The same happens when a new post is found on a feed, the tag is found and the post id is added to the post collection.
It’s a bit more complicated with unread posts, because the difference has to be calculated since last checked from the feeds a user has subscribed to, but the basics are still the same.
Have a table with only three integers is extremely space conservative and fast to query, even over an entire tag. If you know a feed id, it’s easy to find all the post ID’s for that feed.
Below is an extremely basic graph of the structure:
Fixing the duplicates
With all this in mind, to fix the duplicates what is needed is simply:
- Iterate all feeds one by one
- Look up the tag id for the feed<->posts relation
- Based on the “sort number”, which is the “created at” timestamp, find all posts from the last three days
- Fetch all posts from the posts key value store based on these IDs
- Based on the GUID of the post, group all posts with the same GUIDS
- Find GUIDs where the total number of posts is larger than 1
- Remove all but one of those post ids
I’m currently running this script that I wrote that does this, and doing one single feed takes less 0.1 seconds. With all our 100 000 feeds it will probably be done very soon.
Problem
As mentioned earlier, post collections basically hold pointers to posts. Each entry in that table is indexed by a composite primary key, based on tag id and the post id.
With the algorithm outlined above it’s very easy to find posts that are duplicates in the feed list. But because of the primary key requiring a tag id, it’s very hard to just do:
DELETE FROM post_collections WHERE post_id = ? # No index, very slow
What we really need is a tag_id as well:
DELETE FROM post_collections WHERE post_id = ? AND tag_id ? # Index, < 0.00s
Therefor I made a decision to not clear the unread and starred lists from duplicate, because they are really easy for the users to clear. Once an unread entry has been removed, it’s gone and can’t appear again without action from the user.
It does have the benefit of not removing starred posts that users have added, if the post in question was a dupe.
Garbage collection
The fix was basically to remove the pointer in the feed list to the post. This means that I am not removing posts from the key value store, which will not break unreads and stars. However most of these posts will eventually not have any links to it, and become in essence a memory leak.
This has always been a problem for us, clearing old posts. To combat this we periodically run scripts to clear out posts that do not have pointers to it. It’s a pretty heavy operation so I can’t run it as often as I’d like.
One thing to note is also that we trim our feeds to only have 1000 posts, which is more posts anyway that any person would reasonably need.
Thanks
Thanks for reading, and if you experience any problems at all with feeder please don’t hesitate to contact: